Dzisiaj chciałem w skrócie opowiedzieć o tym, jak wprowadziłem do projektu nową bibliotekę. Słyszałem o niej już od jakiegoś czasu, ale nie miałem okazji z niej skorzystać. Kiedy lepiej niż teraz?! Tak więc zapraszam do krótkiego wpisu dotyczącego biblioteki Dapper.
Moja historia z ORM i nie tylko
W projektach .NETowych wykorzystywałem kilka sposobów dostępu do bazy danych. Na początku były to DataSety. Do dziś pamiętam ten dramat gdy trzeba było coś zmieniać w zapytaniach, lub wszystkie razy kiedy kod designera się wykrzaczył i trzeba było kombinować dlaczego.
Później przyszła pora na SqlCommand z ADO.NET. Ręczne mapowanie rezultatów zapytań, kolejny raz poprawianie kodu w wielu miejscach przy zmianach. Też nie było kolorowo, ale jednak nie trzeba było utrzymywać DataSetów. No i wydajność była wyśmienita. To już coś.
Następnie pojawił się EntityFramework w podejściu DatabaseFirst. Kolejny raz pojawił się designer, dodawanie tabelek, ale tutaj już nie trzeba było pisać żadnych procedur składowanych w SQL. Szybkie Linq i gotowe. Coś pięknego. Czar prysł dosyć szybko z kilku powodów. Pierwszy z nich to taki, że nie potrafiliśmy z niego dobrze korzystać. Globalny context na cały projekt? Dlaczego nie! Ogromne zapytania w Linq, które pięknie działają lokalnie, ale na produkcji już nie koniecznie. Oj tak! To było tylko kilka grzechów głównych, które popełniliśmy na początku. Kwestie wydajności można było zastąpić procedurami, ale przy takim podejściu w sumie ta praca wygląda jak ta z DataSetami, bleee. Tutaj pojawia się kolejny problem, czyli designer. Jak już wspomniałem, DataSety przebrane w kostium EF, a do tego z gorszą wydajnością. Nie będę tutaj dalej ciągnął tego wątku, bo to worek bez dna.
Następnie pojawił się EntityFramework, ale już taki „prawdziwy” przy podejściu CodeFirst. Kwestie problemów z wydajnością zapytań pozostają, ale nie mamy już tego przeklętego designera. Chociaż tyle. W tym momencie miałem już dużo większe doświadczenie i wiedziałem, że nie wszystko złoto co się świeci. Do prostych zapytań, jak najbardziej! Praca jest wtedy szybka, nie przejmujemy się za bardzo warstwą bazy danych. Sprawdzamy jedynie, czy EF nie wypluwa jakiegoś kosmicznego zapytania do BD (zawsze jest ono kosmiczne, ale chodzi o to, żeby dobrze działało) i voilà. Jest pięknie. Gdy mamy jakieś skomplikowane zapytanie, nie bójmy się napisać procedury, to nie jest takie złe jeżeli nie musimy tego robić za każdym razem. Na temat EF jest wiele artykułów, wiele z nich twierdzi wręcz, że ta technologia nie nadaje się do niczego. Moim zdaniem w większości przypadków takie podejście może być wystarczające (tak jak w przypadku mojego projektu), ale nie zawsze. Można sprawić, że takie rozwiązanie będzie działało bardzo szybko, ale stracimy wtedy ostatnie zalety, jakie daje EF, np. automatyczne sprawdzanie zmian. Jeżeli zależy nam na wydajności bez kompromisów, trzeba sięgnąć po coś innego.
Dapper
No i tak oto przechodzimy do Dappera. Jak można przeczytać na jego stronie, Dapper to prosty mapper obiektów dla .NET, który rozszerza interfejs IDbConnection. Jako jego główne zalety wymienić można wydajność oraz to, że nie jest ograniczany w żaden sposób przez typ bazy danych z jakiego korzystamy. Wszystkie typy, obsługiwane w .NET ADO np. SqlLite, Firebird, Oracle, MySQL, PosgreSQL czy SQL Server.
Po dwóch dniach odkąd zacząłem z nim pracować, muszę przyznać, że jestem mile zaskoczony. Prawda, trzeba pisać kod SQL, ale samo użycie biblioteki jest bajecznie proste, co zaraz zademonstruje na przykładach. Mamy tutaj zalety EF, gdzie nie trzeba mapować obiektów ręcznie, oraz czystego ADO.NET, gdzie nie trzeba utrzymywać żadnych designerów czy wielkich klas DbContextu. W moim przypadku nie jest to do końca prawda, bo EF służy mi do zarządzania użytkownikami w ASP.NET Identity oraz do wykonywania migracji. Tak więc nie pozbędę się EF z projektu. Prawda jest taka, że na moje potrzeby wystarcza on całkowicie, chodzi tutaj bardziej o naukę.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
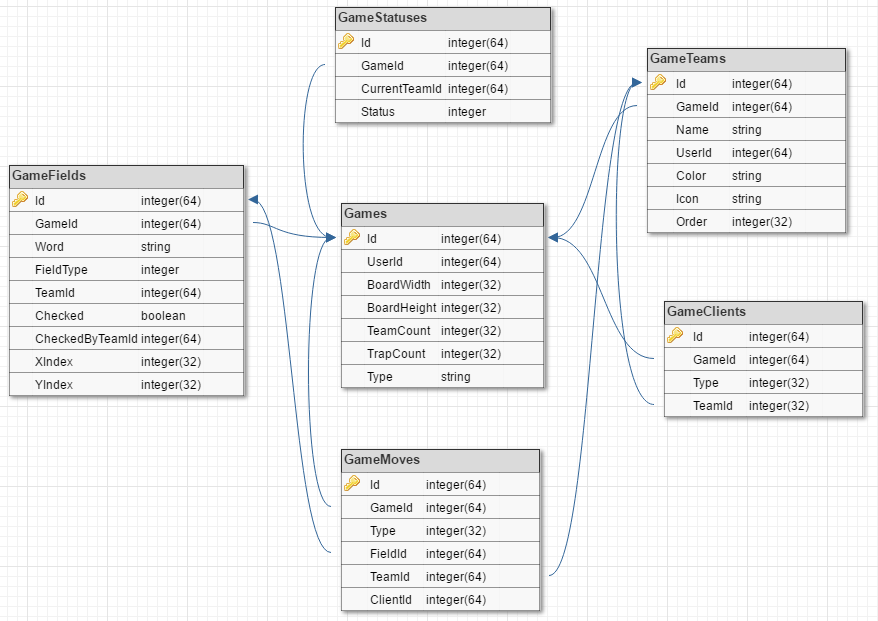
//Saving new game public async Task<GameCreated> SaveNewGame(GameCreate model) { var entity = mapper.Map<Game>(model); entity.CreationDate = timeProvider.GetCurrentTime(); using (var connection = connectionFactory.CreateConnection()) { var game = await connection .QueryFirstAsync<GameCreated>(CreateGameQuery, entity); return game; } } |
Ten prosty kawałek dodaje nowy wiersz i jednocześnie wyciąga dane z bazy danych. Najpierw mapujemy model z danymi gry na encje, dodajemy datę zapisu (moglibyśmy to zrobić na poziomie zapytania, ale wolę takiej logiki nie wydzielać z systemu). Później otwieramy połączenie. Tutaj wykorzystuję fabrykę, która pobiera z konfiguracji connection string do bazy. Na interfejsie IDbConnection wykonujemy metodę QueryFirstAsync, która pobiera i mapuje pierwszy wynik zapytania na wskazany typ obiektu i go zwraca. Nie ma tutaj niczego skomplikowanego.
|
1 2 3 4 5 6 7 8 9 10 11 |
//Database query string private const string CreateGameQuery = @"INSERT INTO GAMES (Name, BoardWidth, BoardHeight, TeamCount, TrapCount, Type, EndMode, UserId, CreationDate, LanguageId) OUTPUT INSERTED.[Id], INSERTED.[BoardWidth], INSERTED.[BoardHeight], INSERTED.[TrapCount], INSERTED.[LanguageId] VALUES (@Name, @BoardWidth, @BoardHeight, @TeamCount, @TrapCount, @Type, @EndMode, @UserId, @CreationDate, @LanguageId)"; |
Powyżej jeszcze zapytanie które jest wykonywane. Od razu pobierane są dane, które chce zwrócić na początek. Wszystko wykonane w jednym odwołaniu do bazy danych. Bardzo miło.
Do dyspozycji mamy jeszcze inne metody, które działają bardzo podobnie, np. Execute, która nie zwraca danych z bazy. Możemy przekazać obiekt transakcji, dzięki czemu możemy wykonać rollback zapytań w razie potrzeby. Taka dygresja, tutaj przekonałem się o tym, że .NET Core jeszcze raczkuje, ponieważ nie posiada w obecnej wersji TransactionScope, znanego z poprzednich wersji frameworka. Kolejna ciekawa opcja to możliwość wykonywania wielu zapytań w jednym odwołaniu do bazy poprzez QueryMultiple. Nie będę rozpisywał się za dużo o przykładach, ponieważ pełno ich w sieci, między innymi nas tronie którą podałem na początku tego posta.
Podsumowanie
Moje doświadczenia z Dapperem są na razie bardzo pozytywne. Nie wiem, czy będę do wykorzystywał do wszystkich zapytań w moim projekcie, ale na pewno do tych bardziej skomplikowanych sięgnę właśnie po niego. Zachęcam Was do zapoznania się z tą biblioteką.