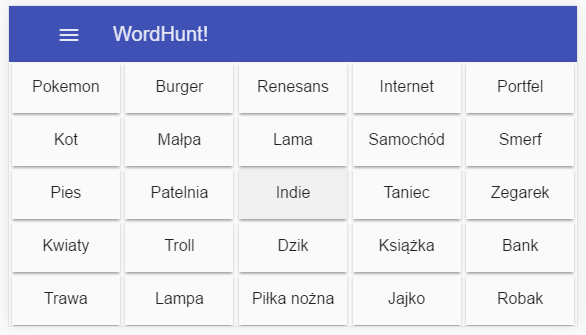
Dzisiaj pokażę jak wygląda plansza do gry. Przyznaję, że spodziewałem się że ten element zostanie skończony już dawno, ale wyszło jak wyszło. Zadanie to sprawiło mi więcej problemów niż się spodziewałem, ale jestem w miarę zadowolony z tego co otrzymałem.
Plansza i jej elementy
Jeżeli chodzi o styl, pozostawia ona jeszcze sporo do życzenia, ale pola na planszy zachowują się tak jak chciałem. Dostosowują się do wielkości ekranu, w pełni wypełniając całą dostępną przestrzeń.
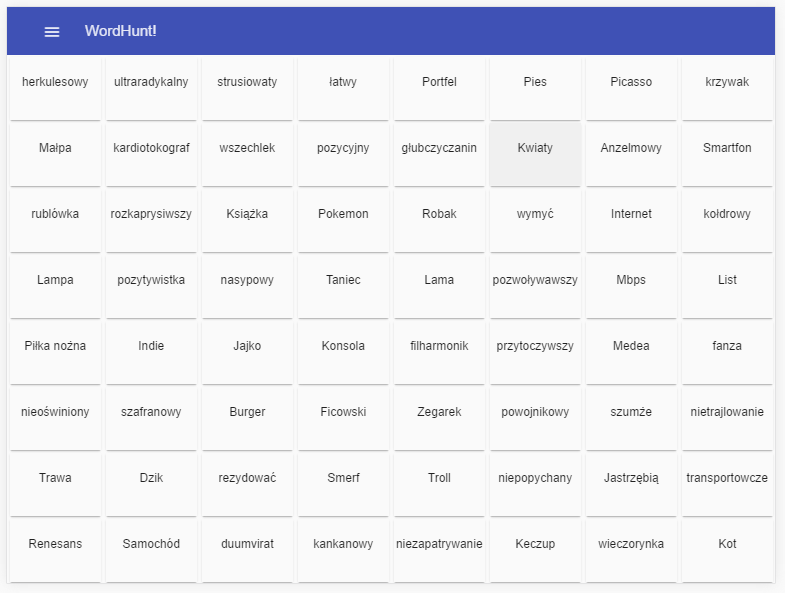
W przypadku, gdy plansza posiada więcej słów i pola nie będą się mieścić w całości, wyrazy zostaną ucięte. W przyszłości czcionka będzie zmieniać rozmiar w zależności od wielkości ekranu i długości słowa, dzięki czemu unikniemy takich sytuacji. Na troszkę większych urządzeniach np. tabletach wyświetlanie działa tak jak należy, nawet na największej możliwej planszy 8×8.
Teraz, gdy plansza jest już w takim stanie, zaczynam dodawać pozostałe fragmenty. Na tą chwilę jest jeszcze menu boczne, gdzie będą dodatkowe informacje oraz opcje. Żeby nie marnować miejsca, jest ono ukryte. Gdy je otworzymy, menu pojawia się nad planszą.
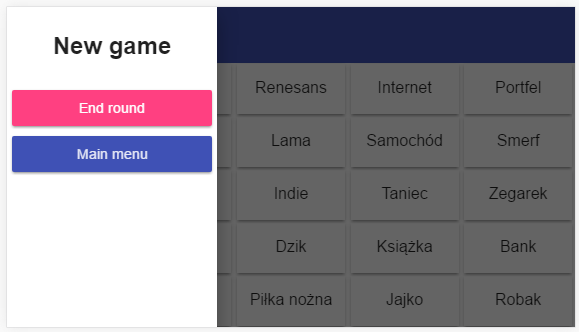
Obecnie obsługuję jedynie przycisk pominięcia rundy, dzięki czemu kolejna drużyna może wykonać ruch. Jutro dodam obsługę „odsłonięcia” pola, czyli jedną z najważniejszych rzeczy do zrobienia.
Jak to wygląda pod maską?
Skoro już zademonstrowałem jak plansza wygląda, pokażę teraz jak to działa. Wygląd aplikacja zawdzięcza komponentom Angular Material Design, natomiast sam layout planszy działa na bazie Flex Layout. Obie biblioteki są w wersji beta, ale większych bugów nie znalazłem. Muszę jednak powiedzieć, że próg wejścia do tych technologi jest troszkę większy niż to, co spotyka nas przy pierwszym kontakcie z popularnym konkurentem, czyli poczciwym Bootstrapem. Nie ma jednak tragedii i coś nawet da się z tym zrobić.
Ekran gry podzielony jest na kilka elementów. Kod głównego komponentu, na którym umieszczone są wszystkie elementy wygląda następująco:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
<!--Main component--> <md-sidenav-container fullscreen> <md-sidenav #sidenav mode="over"> <game-sidenav></game-sidenav> </md-sidenav> <md-toolbar color="primary" class="fixed-toolbar"> <button md-button (click)="sidenav.toggle()"> <i class="material-icons app-toolbar-menu">menu</i> </button> WordHunt! </md-toolbar> <game-board></game-board> </md-sidenav-container> |
Kontener, w którym wyświetlane jest menu boczne, toolbar gdzie jest tytuł aplikacji, a będą także ikony drużyn oraz plansza do gry. Tutaj nie musiałem dużo majstrować przy stylach. Jedynie toolbar wymagał drobnych modyfikacji.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
// Styles @import '../styles/game.scss'; .fixed-toolbar { @include when-xs { height: $toolbar-height-xs; } @include when-sm { height: $toolbar-height-sm; } } |
Ręcznie modyfikuję rozmiar górnego paska aplikacji, ponieważ zmieniał się on przy zmianie wielkości okna. Powodowało to, że plansza do gry odrobinę się przesuwała i wychodziła poza ekran.
W bazowej klasie ze stylami zdefiniowałem mixin, który wykorzystujemy w innych komponentach, tak jak powyżej. Dzięki temu dokładnie i w łatwy sposób sterujemy stylami w zależności od wielkości ekranu. Był on szczególnie potrzebny w przypadku planszy, ponieważ przesuwała się ona w dół o wysokość paska górnego.
Sam kod planszy jest dosyć krótki, ale powiedziałbym że intensywny. Mamy tutaj dwa layouty fxLayout: column i row. Kolumnowy sprawia, że każdy rząd zabiera odpowiednią ilość miejsca w pionie. Dzięki temu plansza wypełnia całą przestrzeń. Każdy rząd składa się z komponentu game-field, który wyświetla słowa i odpowiadać będzie za kliknięcie na element.
|
1 2 3 4 5 6 7 8 |
<!--Game board--> <div class="board-container"> <div fxFlexFill fxLayout="column" fxLayoutAlign="space-around none"> <div fxLayout="row" *ngFor="let row of rows" [fxFlex]="colFlex" fxLayoutAlign="space-around none"> <game-field *ngFor="let field of row" [field]="field" [fxFlex]="rowFlex"></game-field> </div> </div> </div> |
Wartość fxFlex, która definiuje nam jak dużo przestrzeni ma wykorzystać każdy blok, wyliczana jest w kodzie po załadowaniu danych gry. Na podstawie ilości rzędów i kolumn dodajemy odpowiednią wartość do każdego elementu. Wartość bazowa baseFlexValue, od której liczymy wielkość elementów sprawia, że otrzymamy małe odstępy pomiędzy polami, które będą zmieniały wielkość w zależności od wielkości ekranu. Gdyby było tam 100, nie mielibyśmy przerw. Można to oczywiście zaprogramować inaczej, np. poprzez margin pól gry, ale na razie zostawię to tak jak jest.
|
1 2 3 4 5 6 7 |
//Calculate values of fxFlex private calculateFlex() { const baseFlexValue: number = 95; this.colFlex = baseFlexValue / this.game.boardHeight; this.rowFlex = baseFlexValue / this.game.boardWidth; } |
Jeżeli chodzi o stylowanie tego komponentu, trzeba było dodać obliczenie wielkości planszy z uwzględnieniem paska górnego. Bez tego plansza była przesunięta o jego wysokość.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
//Game board style @import '../styles/game.scss'; .game-board { height: 100%; } .board-container { @include when-xs { height: -webkit-calc(100% - #{$toolbar-height-xs}); height: -moz-calc(100% - #{$toolbar-height-xs}); height: calc(100% - #{$toolbar-height-xs}); } @include when-sm { height: -webkit-calc(100% - #{$toolbar-height-sm}); height: -moz-calc(100% - #{$toolbar-height-sm}); height: calc(100% - #{$toolbar-height-sm}); } } |
Tutaj uwaga! calc nie przyjmuje zmiennych z SASSa, chyba że opakujemy je w nawiasy klamrowe poprzedzone hasztagiem. Trochę mi zajęło zanim na to wpadłem… Szczerze, to boję się tego ruszać, bo już raz coś zmieniłem, co sprawiło że zepsułem cały ekran gry i naprawiałem go dobrych kilka minut. Szybko nauczyłem się robić częste commity, o których zdarza mi się zapomnieć. Kodu nie jest wiele, ale jako że nie jestem mistrzem CSS, trochę mi zajęło znalezienie takiej konfiguracji.
Podsumowanie
Plansza w wersji beta gotowa, teraz dodanie obsługi wykrywania pól oraz mapy dla kapitanów. Gdy to będzie gotowe, MVP projektu będzie skończone. Mam nadzieję że przed końcem konkursu!